| Supported Target Versions |
|---|
| Pacemaker : Pacemaker 1.1.23-1.el7_9.1 |
| Non-PaceMaker : RGManager - 6.5 ( Linux nodes : redhat-6.2.0) |
Application Version and Upgrade Details
| Application Version | Bug fixes / Enhancements |
|---|---|
| 2.0.0 |
|
| 1.0.9 | Support added for metric label changes. |
| 1.0.8 | Fixed discovery response parsing issue. |
Click here to view the earlier version updates
| Application Version | Bug fixes / Enhancements |
|---|---|
| 1.0.7 | Full discovery support added. |
| 1.0.6 |
|
| 1.0.5 | Monitoring parsing issues have been fixed. |
| 1.0.4 |
|
| 1.0.3 | Added support to alert on gateway in case initial discovery fails with connectivity/authorization issues. |
| 1.0.2 | Fixed the metrics graphs issue. |
| 1.0.1 | Initial sdk2.0 app discovery & monitoring implementation. |
Introduction
Linux cluster is a group of Linux computers or nodes, storage devices that work together and are managed as a single system. A traditional clustering configuration has two nodes that are connected to shared storage (typically a SAN). With Linux clustering, an application is run on one node, and clustering software is used to monitor its operation.
A Linux cluster provides faster processing speed, larger storage capacity, better data integrity, greater reliability and wider availability of resources.
Failover
Failover is a process. Whenever a primary system, network or a database fails or is abnormally terminated, then a Failover acts as a standby which helps resume these operations.
Failover Cluster
Failover cluster is a set of servers that work together to provide High Availability (HA) or Continuous availability (CA). As mentioned earlier, if one of the servers goes down another node in the cluster can take over its workload with minimal or no downtime. Some failover clusters use physical servers whereas others involve virtual machines (VMs).
CA clusters allow users to access and work on the services and applications without any incidence of timeouts (100% availability), in case of a server failure. HA clusters, on the other hand, may cause a short hiatus in the service, but system recovers automatically with minimum downtime and no data loss.
A cluster is a set of two or more nodes (servers) that transmit data for processing through cables or a dedicated secure network. Even load balancing, storage or concurrent/parallel processing is possible through other clustering technologies.
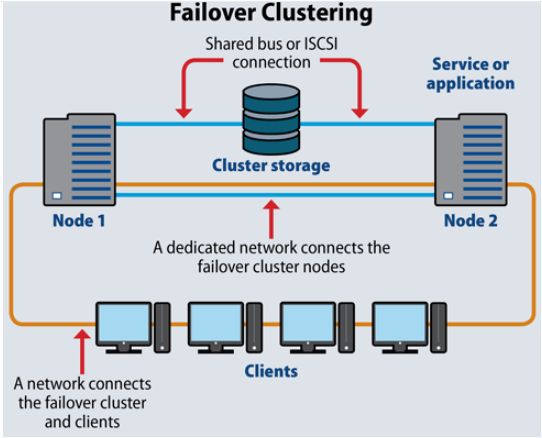
If you look at the above image, Node 1 and Node 2 have common shared storage. Whenever one node goes down, the other one will pick up from there. These two nodes have one virtual IP that all other clients connect to.
Let us take a look at the two failover clusters, namely High Availability Failover Clusters and Continuous Availability Failover Clusters.
High Availability Failover Clusters
In case of High Availability Failover Clusters, a set of servers share data and resources in the system. All the nodes have access to the shared storage.
High Availability Clusters also include a monitoring connection that servers use to check the “heartbeat” or health of the other servers. At any time, at least one of the nodes in a cluster is active, while at least one is passive.
Continuous Availability Failover Clusters
This system consists of multiple systems that share a single copy of a computer’s operating system. Software commands issued by one system are also executed on the other systems. In case of a failover, the user can check critical data in a transaction.
There are a few Failover Cluster types like Linux Server Failover Cluster (WSFC), VMware Failover Clusters, SQL Server Failover Clusters, and Red Hat Linux Failover Clusters.
Prerequisites
- OpsRamp Classic Gateway 14.0.0 and above.
- OpsRamp Nextgen Gateway 14.0.0 and above.
Note: OpsRamp recommends using the latest Gateway version for full coverage of recent bug fixes, enhancements, etc. - Prerequisites for Pacemaker
- Credentials: root / non-root privileges with a member of “haclient” group.
- Cluster management: Pacemaker
- Accessibility: All nodes within a cluster should be accessible by a single credential set.
- For non-root users: Update “~/.bashrc” file with “pcs” command path across all cluster nodes.
Ex: export PATH=$PATH:/usr/sbin -> as a new line in ~/.bashrc file.
- Prerequisites for RGManager (non-pacemaker)
Credentials: should provide access to both root and non-root users.
Cluster management: RGManager
Accessibility: All the nodes within a cluster should be accessible by a single credential set.
For non-root users: Update the following commands in “etc/sudoers” file to provide access for non-root users to execute these commands.
“/usr/sbin/cman_tool nodes,/usr/sbin/cman_tool status,/usr/sbin/clustat -l,/sbin/service cman status,/sbin/service rgmanager status,/sbin/service corosync status,/usr/sbin/dmidecode -s system-uuid,/bin/cat /sys/class/dmi/id/product_serial”
Note: Usually a linux cluster will be configured with a virtual-ip normally called as cluster-virtual-ip.We use this Ip for adding configurations during the installation of integration.If the cluster-virtual-ip is not configured give the ip address of the reachable node associated with the cluster.
Hierarchy of Linux Cluster
Cluster
-Nodes
Application Migration
Check for the gateway version as a prerequisite step - classic gateway-12.0.1 and above.
Notes:- You only have to follow these steps when you want to migrate from sdk 1.0 to sdk 2.0.
- For the first time installation below steps are not required.
Disable all configurations associated with sdk 1.0 adaptor integration application.
Install and Add the configuration to that sdk 2.0 application.
Note: refer to Configure and Install the Linux Failover Cluster Integration & View the Linux Failover Cluster Details sections of this document.Once all discoveries are completed with the sdk 2.0 application, follow any one of the approaches.
- Direct uninstallation of the sdk 1.0 adaptor application through the uninstall API with skipDeleteResources=true in the post request
End-Point:https://{{host}}/api/v2/tenants/{tenantId}/integrations/installed/{installedIntgId}
Request Body:{ "uninstallReason": "Test", "skipDeleteResources": true }
(OR) - Delete the configuration one by one through the Delete adaptor config API with the request parameter as skipDeleteResources=true
End-Point:https://{{host}}/api/v2/tenants/{tenantId}/integrations/installed/config/{configId}?skipDeleteResources=true. - Finally, uninstall the adaptor application through API with skipDeleteResources=true in the post request.
End-Point:https://{{host}}/api/v2/tenants/{tenantId}/integrations/installed/{installedIntgId}
Request Body:{ "uninstallReason": "Test", "skipDeleteResources": true }
- Direct uninstallation of the sdk 1.0 adaptor application through the uninstall API with skipDeleteResources=true in the post request
Supported Metrics
Click here to view the supported metrics
Resource Type: Cluster
| Native Type | Metric Names | Display Name | Metric Label | Unit | Application Version | Pacemaker / RGManager | Description |
|---|---|---|---|---|---|---|---|
| Linux Cluster | linux_cluster_nodes_status | Cluster Node Status | Availability | 1.0.0 | Both | Status of each nodes present in linux cluster. 0 - offline, 1- online, 2- standby | |
| linux_cluster_system_OS_Uptime | System Uptime | Availability | m | 1.0.0 | Both | Time lapsed since last reboot in minutes | |
| linux_cluster_system_cpu_Load | System CPU Load | Usage | 1.0.0 | Both | Monitors the system's last 1min, 5min and 15min load. It sends per cpu core load average. | ||
| linux_cluster_system_cpu_Utilization | System CPU Utilization | Usage | % | 1.0.0 | Both | The percentage of elapsed time that the processor spends to execute a non-Idle thread(This doesn't includes CPU steal time). | |
| linux_cluster_system_memory_Usedspace | System Memory Used Space | Usage | Gb | 1.0.0 | Both | Physical and virtual memory usage in GB | |
| linux_cluster_system_memory_Utilization | System Memory Utilization | Usage | % | 1.0.0 | Both | Physical and virtual memory usage in percentage. | |
| linux_cluster_system_cpu_Usage_Stats | System CPU Usage Statistics | Usage | % | 1.0.0 | Both | Monitors cpu time in percentage spent in various program spaces. User - The processor time spent running user space processes. System - The amount of time that the CPU spent running the kernel. IOWait - The time the CPU spends idle while waiting for an I/O operation to complete. Idle - The time the processor spends idle. Steal - The time virtual CPU has spent waiting for the hypervisor to service another virtual CPU running on a different virtual machine. Kernal Time Total Time. | |
| linux_cluster_system_disk_Usedspace | System Disk UsedSpace | Usage | Gb | 1.0.0 | Both | Monitors disk used space in GB | |
| linux_cluster_system_disk_Utilization | System Disk Utilization | Usage | % | 1.0.0 | Both | Monitors disk utilization in percentage. | |
| linux_cluster_system_disk_Inode_Utilization | System Disk Inode Utilization | Usage | % | 1.0.0 | Both | This monitor is to collect DISK Inode metrics for all physical disks in a server. | |
| linux_cluster_system_disk_freespace | System FreeDisk Usage | Usage | Gb | 1.0.0 | Both | Monitors the Free Space usage in GB | |
| linux_cluster_system_network_interface_Traffic_In | System Network In Traffic | Performance | Kbps | 1.0.0 | Both | Monitors In traffic of each interface for Linux Devices | |
| linux_cluster_system_network_interface_Traffic_Out | System Network Out Traffic | Performance | Kbps | 1.0.0 | Both | Monitors Out traffic of each interface for Linux Devices | |
| linux_cluster_system_network_interface_Packets_In | System Network In packets | Performance | packets/sec | 1.0.0 | Both | Monitors in Packets of each interface for Linux Devices | |
| linux_cluster_system_network_interface_Packets_Out | System Network out packets | Performance | 1.0.0 | Both | Monitors Out packets of each interface for Linux Devices | ||
| linux_cluster_system_network_interface_Errors_In | System Network In Errors | Availability | Errors per Sec | 1.0.0 | Both | Monitors network in errors of each interface for Linux Devices | |
| linux_cluster_system_network_interface_Errors_Out | System Network Out Errors | Availability | Errors per Sec | 1.0.0 | Both | Monitors Network Out traffic of each interface for Linux Devices | |
| linux_cluster_system_network_interface_discards_In | System Network In discards | Availability | psec | 1.0.0 | Both | Monitors Network in discards of each interface for Linux Devices | |
| linux_cluster_system_network_interface_discards_Out | System Network Out discards | Availability | psec | 1.0.0 | Both | Monitors network Out Discards of each interface for Linux Devices | |
| linux_cluster_service_status_Pacemaker | Pacemaker Service Status | Availability | 1.0.0 | Pacemaker | Pacemaker High Availability Cluster Manager. The status representation as follows : 0 - "failed", 1 - "active" & 2 - "unknown" | ||
| linux_cluster_service_status_Corosync | Corosync Service Status | Availability | 1.0.0 | Pacemaker | The Corosync Cluster Engine is a Group Communication System. The status representation as follows : 0 - "failed", 1 - "active" & 2 - "unknown" | ||
| linux_cluster_service_status_PCSD | PCSD Service Status | Availability | 1.0.0 | Pacemaker | PCS GUI and remote configuration interface. The status representation as follows : 0 - "failed", 1 - "active" & 2 - "unknown" | ||
| linux_cluster_Online_Nodes_Count | Online Nodes Count | Availability | count | 1.0.0 | Both | Online cluster nodes count. | |
| linux_cluster_Failover_Status | Cluster FailOver Status | Availability | 1.0.0 | Both | Provides the details about cluster failover status. The integer representation as follows, 0 - cluster is running on the same node, 1 - there is failover happened. | ||
| linux_cluster_node_Health | Cluster Node Health Percentage | Availability | % | 1.0.0 | Both | This metrics gives the info about the percentage of online linux nodes available within a cluster. | |
| linux_cluster_service_Status | Linux Cluster Service Status | Availability | 1.0.0 | Both | Cluster Services Status. The status representation as follows : 0 - disabled, 1-blocked, 2 - failed, 3 - stopped, 4 - recovering, 5 - stopping, 6 - starting, 7 - started, 8 - unknown | ||
| linux_cluster_service_status_rgmanager | RGManager Service Status | Availability | 1.0.0 | RGManager | RGManager Service Status. The status representation as follows : 0 - \"failed\", 1 - \"active\" , 2 - \"unknown\" | ||
| linux_cluster_service_status_CMAN | CMAN Service Status | Availability | 1.0.0 | RGManager | CMAN Service Status. The status representation as follows : 0 - \"failed\", 1 - \"active\" \u0026 2 - \"unknown\" | ||
| linux_cluster_fence_status | Linux Cluster Fence Status | Availability | 2.0.0 | Pacemaker | Cluster Fence Status. The status representation as follows : 0 - disabled, 1-blocked, 2 - failed, 3 - stopped, 4 - recovering, 5 - stopping, 6 - starting, 7 - started, 8 - unknown | ||
| linux_cluster_fence_failover_status | Cluster Fence FailOver Status | Availability | 2.0.0 | Pacemaker | Provides the details about cluster fence failover status. The integer representation as follows , 0 - fence is running on the same node , 1 - there is failover happened | ||
| linux_cluster_service_failover_status | Cluster Service FailOver Status | Availability | 2.0.0 | Pacemaker | Provides the details about cluster service failover status. The integer representation as follows , 0 - resource group is running on the same node , 1 - there is failover happened | ||
| linux_cluster_failed_actions_count | Cluster Failed Resource Actions Count | Availability | Count | 2.0.0 | Pacemaker | Provides the cluster failed resource actions Count |
Resource Type: Server
| Native Type | Metric Names | Display Name | Metric Label | Unit | Application Version | Pacemaker / RGManager | Description |
|---|---|---|---|---|---|---|---|
| Linux Cluster Node | linux_node_system_OS_Uptime | System Uptime | Availability | m | 1.0.0 | Both | Time lapsed since last reboot in minutes |
| linux_node_system_cpu_Load | System CPU Load | Usage | 1.0.0 | Both | Monitors the system's last 1min, 5min and 15min load. It sends per cpu core load average. | ||
| linux_node_system_cpu_Utilization | System CPU Utilization | Usage | % | 1.0.0 | Both | The percentage of elapsed time that the processor spends to execute a non-Idle thread(This doesn't includes CPU steal time) | |
| linux_node_system_memory_Usedspace | System Memory Used Space | Usage | Gb | 1.0.0 | Both | Physical and virtual memory usage in GB | |
| linux_node_system_memory_Utilization | System Memory Utilization | Usage | % | 1.0.0 | Both | Physical and virtual memory usage in percentage. | |
| linux_node_system_cpu_Usage_Stats | System CPU Usage Statistics | Usage | % | 1.0.0 | Both | Monitors cpu time in percentage spent in various program spaces. User - The processor time spent running user space processes. System - The amount of time that the CPU spent running the kernel. IOWait - The time the CPU spends idle while waiting for an I/O operation to complete. Idle - The time the processor spends idle. Steal - The time virtual CPU has spent waiting for the hypervisor to service another virtual CPU running on a different virtual machine. Kernal Time Total Time | |
| linux_node_system_disk_Usedspace | System Disk UsedSpace | Usage | Gb | 1.0.0 | Both | Monitors disk used space in GB | |
| linux_node_system_disk_Utilization | System Disk Utilization | Usage | % | 1.0.0 | Both | Monitors disk utilization in percentage | |
| linux_node_system_disk_Inode_Utilization | System Disk Inode Utilization | Usage | % | 1.0.0 | Both | This monitor is to collect DISK Inode metrics for all physical disks in a server. | |
| linux_node_system_disk_freespace | System FreeDisk Usage. | Usage | Gb | 1.0.0 | Both | Monitors the Free Space usage in GB | |
| linux_node_system_network_interface_Traffic_In | System Network In Traffic. | Performance | Kbps | 1.0.0 | Both | Monitors In traffic of each interface for Linux Devices | |
| linux_node_system_network_interface_Traffic_Out | System Network Out Traffic | Performance | Kbps | 1.0.0 | Both | Monitors Out traffic of each interface for Linux Devices | |
| linux_node_system_network_interface_Packets_In | System Network In packets | Performance | packets/sec | 1.0.0 | Both | Monitors in Packets of each interface for Linux Devices | |
| linux_node_system_network_interface_Packets_Out | System Network out packets | Performance | packets/sec | 1.0.0 | Both | Monitors Out packets of each interface for Linux Devices | |
| linux_node_system_network_interface_Errors_In | System Network In Errors | Availability | Errors per Sec | 1.0.0 | Both | Monitors network in errors of each interface for Linux Devices | |
| linux_node_system_network_interface_Errors_Out | System Network Out Errors | Availability | Errors per Sec | 1.0.0 | Both | Monitors Network Out traffic of each interface for Linux Devices | |
| linux_node_system_network_interface_discards_In | System Network In discards | Availability | psec | 1.0.0 | Both | Monitors Network in discards of each interface for Linux Devices | |
| linux_node_system_network_interface_discards_Out | System Network Out discards | Availability | psec | 1.0.0 | Both | Monitors network Out Discards of each interface for Linux Devices |
Default Monitoring Configurations
Linux Failover Cluster application has default Global Device Management Policies, Global Templates, Global Monitors and Global metrics in OpsRamp. Users can customize these default monitoring configurations as per their business use cases by cloning respective Global Templates, and Global Device Management Policies. OpsRamp recommends doing this activity before installing the application to avoid noise alerts and data.
Default Global Device Management Policies
OpsRamp has a Global Device Management Policy for each Native Type of Lnux Failover Cluster. You can find those Device Management Policies at Setup > Resources > Device Management Policies, search with suggested names in global scope. Each Device Management Policy follows below naming convention:
{appName nativeType - version}Ex: linux-failover-cluster Linux Cluster - 1 (i.e, appName = linux-failover-cluster, nativeType = Linux Cluster, version = 1)
Default Global Templates
OpsRamp has a Global template for each Native Type of LINUX-FAILOVER-CLUSTER. You can find those templates at Setup > Monitoring > Templates, search with suggested names in global scope. Each template follows below naming convention:
{appName nativeType 'Template' - version}Ex: linux-failover-cluster Linux Cluster Template - 1 (i.e, appName = linux-failover-cluster, nativeType = Linux Cluster, version = 1)
Default Global Monitors
OpsRamp has a Global Monitors for each Native Type which has monitoring support. You can find those monitors at Setup > Monitoring > Monitors, search with suggested names in global scope. Each Monitors follows below naming convention:
{monitorKey appName nativeType - version}Example: Linux Failover Cluster Monitor linux-failover-cluster Linux Cluster 1 (i.e, monitorKey = Linux Failover Cluster Monitor, appName = linux-failover-cluster, nativeType = Linux Cluster, version = 1)
Configure and Install the Linux Failover Cluster Integration
- From All Clients, select a client.
- Navigate to Setup > Account.
- Select the Integrations and Apps tab.
- The Installed Integrations page, where all the installed applications are displayed. Note: If there are no installed applications, it will navigate to the Available Integrations and Apps page.
- Click + ADD on the Installed Integrations page. The Available Integrations and Apps page displays all the available applications along with the newly created application with the version.
- Search for the application using the search option available. Alternatively, use the All Categories option to search.
- Click ADD in the Linux Failover Cluster application.
- In the Configurations page, click + ADD. The Add Configuration page appears.
- Enter the below mentioned BASIC INFORMATION:
| Object Name | Description |
|---|---|
| Name | Enter the name for the integration |
| IP Address/Host Name | IP address/host name of the target. |
| Credentials | Select the credentials from the drop-down list. Note: Click + Add to create a credential. |
| Cluster Type | Select Pacemake or RGManager from the Cluster Type drop-down list. |
Note:
- Ip Address/Host Name should be accessible from Gateway.
- Select App Failure Notifications to be notified in case of an application failure that is, Connectivity Exception, Authentication Exception.
- Select the below mentioned Custom Attribute:
| Functionality | Description |
|---|---|
| Custom Attribute | Select the custom attribute from the drop down list box. |
| Value | Select the value from the drop down list box. |
Note: The custom attribute that you add here will be assigned to all the resources that are created by the integration. You can add a maximum of five custom attributes (key and value pair).
- In the RESOURCE TYPE section, select:
- ALL: All the existing and future resources will be discovered.
- SELECT: You can select one or multiple resources to be discovered.
- In the DISCOVERY SCHEDULE section, select Recurrence Pattern to add one of the following patterns:
- Minutes
- Hourly
- Daily
- Weekly
- Monthly
- Click ADD.
Now the configuration is saved and displayed on the configurations page after you save it.
Note: From the same page, you may Edit and Remove the created configuration.
Under the ADVANCED SETTINGS, Select the Bypass Resource Reconciliation option, if you wish to bypass resource reconciliation when encountering the same resources discovered by multiple applications.
Note: If two different applications provide identical discovery attributes, two separate resources will be generated with those respective attributes from the individual discoveries.
Click NEXT.
(Optional) Click +ADD to create a new collector by providing a name or use the pre-populated name.
- Select an existing registered profile.
- Click FINISH.
The application is installed and displayed on the INSTALLED INTEGRATION page. Use the search field to find the installed integration.
Modify the Configuration
See Modify an Installed Integration or Application article.
Note: Select the Linux Failover Cluster application.
View the Linux Failover Cluster Details
To discover resources for HPE StoreOnce:
- Navigate to Infrastructure > Search > OS > Linux Failover Cluster.
- The LINUX FAILOVER CLUSTER page is displayed, select the application name.
- The RESOURCE page appears from the right.
- Click the ellipsis (…) on the top right and select View details.
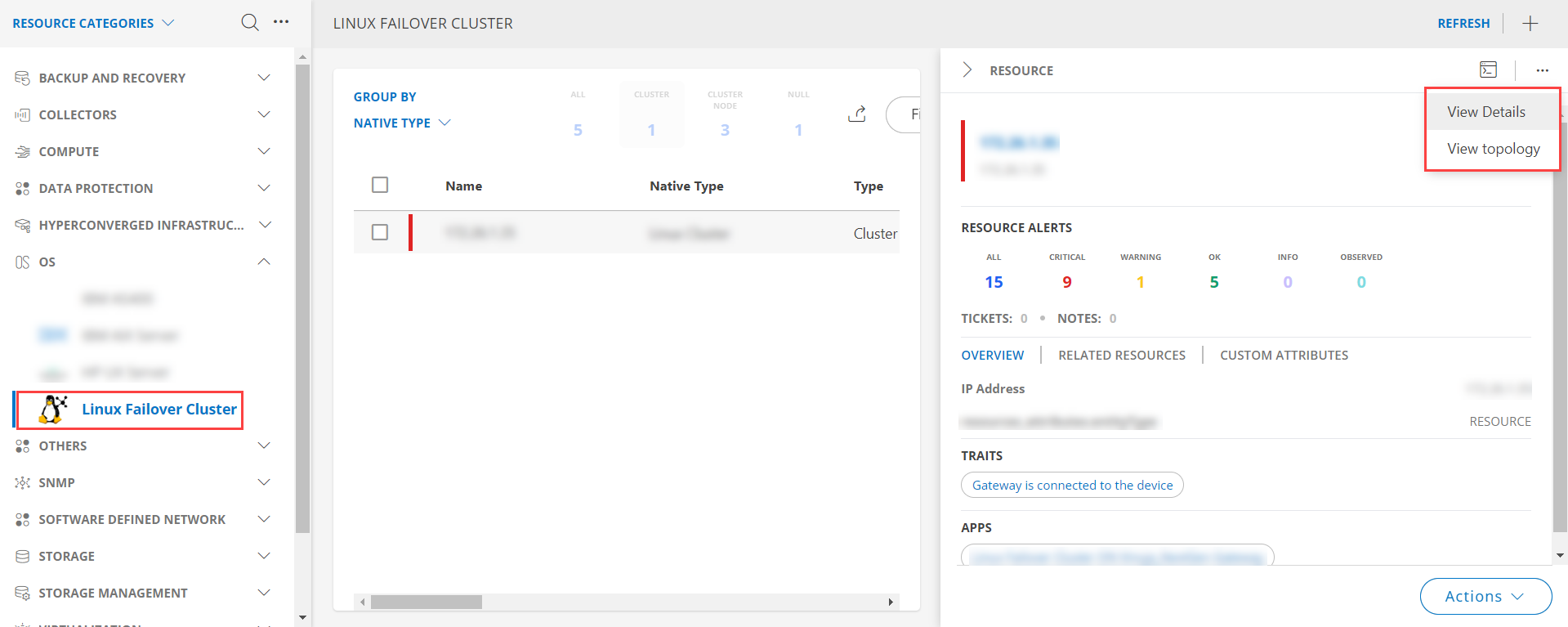
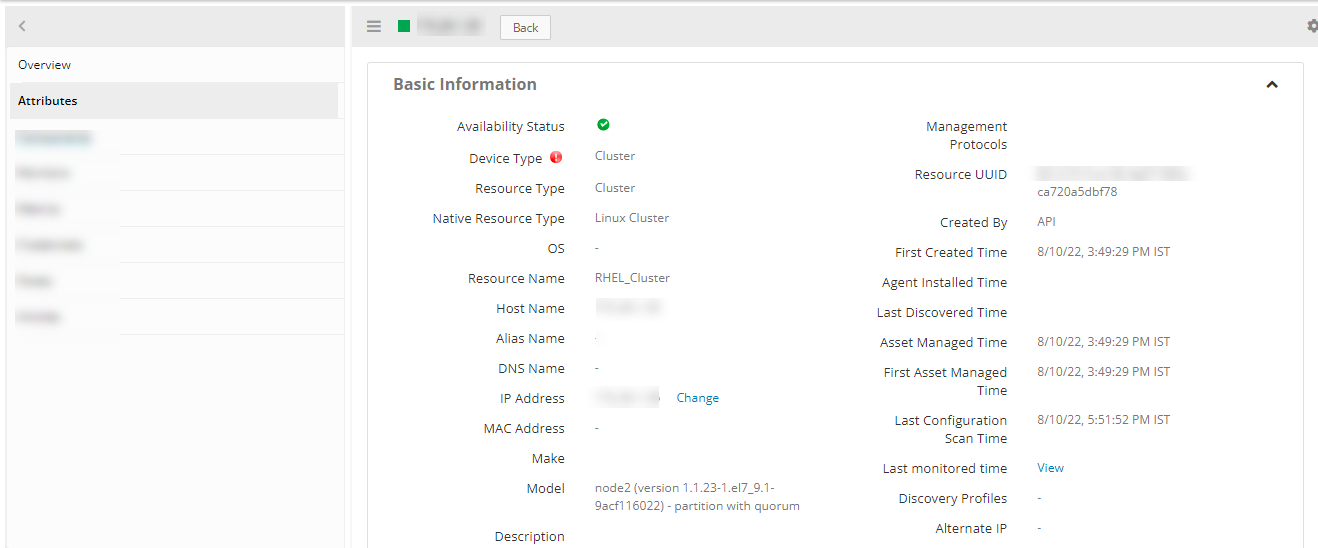
View resource attributes
The discovered resource(s) are displayed under Attributes. In this page you will get the basic information about the resources such as: Resource Type, Native Resource Type, Resource Name, IP Address etc.
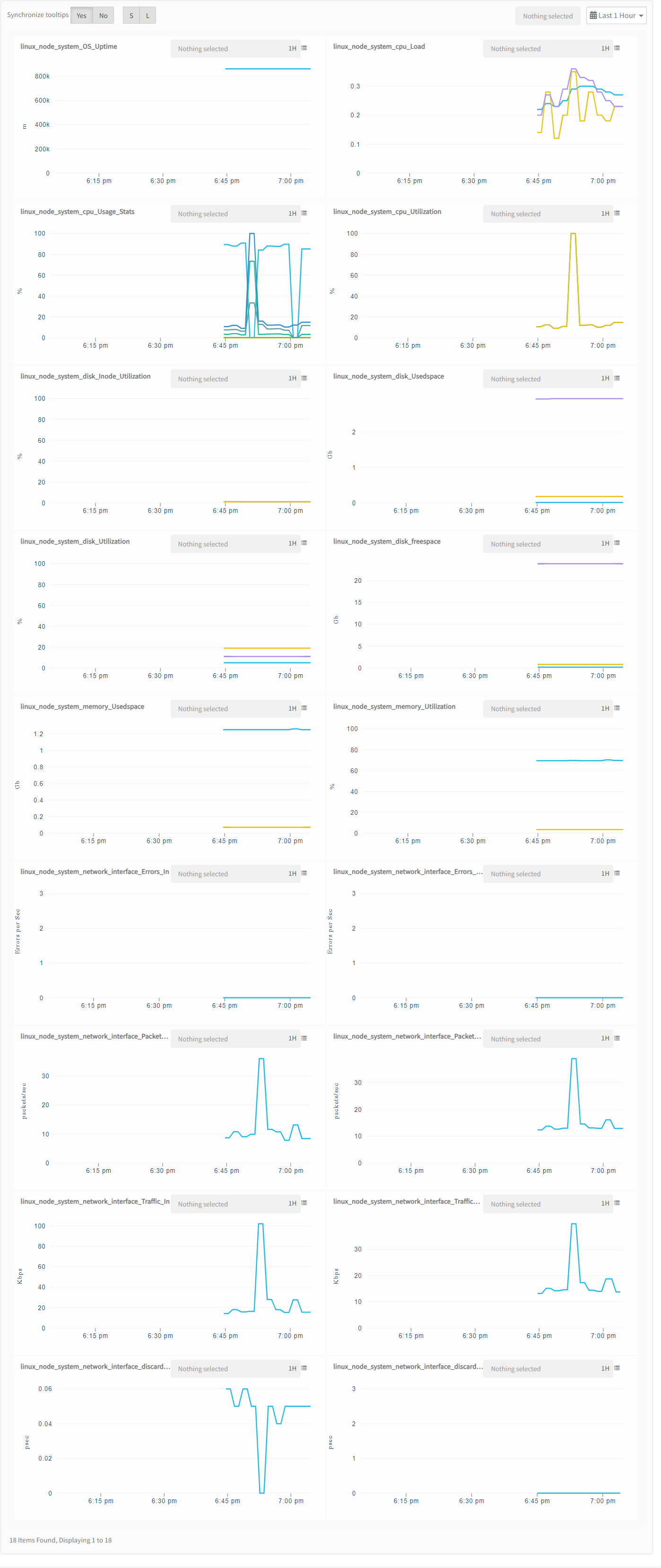
View resource metrics
To confirm Linux Cluster monitoring, review the following:
- Metric graphs: A graph is plotted for each metric that is enabled in the configuration.
- Alerts: Alerts are generated for metrics that are configured as defined for integration.
Supported Alert Custom Macros
Customize the alert subject and description with below macros then it will generate alert based on customisation.
Supported macros keys:
Click here to view the alert subject and description with macros
${resource.name}
${resource.ip}
${resource.mac}
${resource.aliasname}
${resource.os}
${resource.type}
${resource.dnsname}
${resource.alternateip}
${resource.make}
${resource.model}
${resource.serialnumber}
${resource.systemId}
${Custome Attributes in the resource}
${parent.resource.name}
Risks, Limitations & Assumptions
- Application can handle Critical/Recovery failure notifications for below two cases when user enables App Failure Notifications in configuration
- Connectivity Exception
- Authentication Exception
- The application will send duplicate/repeat failure alert notifications for every 6 hours.
- Support for Macro replacement for threshold breach alerts (i.e, customisation for threshold breach alert’s subject, description).
- Application cannot control monitoring pause/resume actions based on above alerts.
- Metrics can be used to monitor Linux-Failover-Cluster resources and can generate alerts based on the threshold values.
- No support of showing activity log and applied time.
- This application supports both Classic Gateway and NextGen Gateway.
- For the metric linux_cluster_failed_actions_count, an alert will be generated if the failed actions count is greater than or equal to 1, and if there is an alert raised on a component then the repeat alert will be generated only after 6 hours on that component if any threshold breach exists. The created alerts will not be healed by the application.
- For metrics linux_cluster_fence_failover_status and linux_cluster_service_failover_status, an alert will be generated if there is a change of the node on which service runs. The created alerts will be healed by the application in the subsequent poll if it is running on the same node.Also the metric graphs will have the discontinuity as we’re setting the component name as service_name:node.
- The minimum supported version for the option to get the latest snapshot metric is Nextgen-14.0.0.